
英偉達大舉進軍CPU,AI推理時代大廠加速推進全棧異構布局
日前Meta與英偉達簽署的一項多年期合同受到廣泛關注,其中約定Meta不僅將采購數百萬顆Blackwell和Rubin GPU,搭建大規模AI數據中心,還采用英偉達Grace CPU作為獨立服務器芯片。這也是該款CPU首次實現大規模部署,表明英偉達在GPU之外,仍致力于大力推進旗下CPU產品線的發展。
而另據最新消息,AMD也在積極推進旗下Instinct MI450(基于Instinct GPU 和代號為“Venice”的第六代AMD EPYC? CPU)的發展,其與Meta簽訂的最新協議中,MI450將被用于Meta下一代AI基礎設施,合同金額達600億美元。
上述事情表明,隨著AI技術不斷迭代發展,計算范式也在不斷演進改變,并對芯片產業的競爭格局產生重大影響,單一計算單元很難滿足多元需求。這使越來越多芯片大廠選擇在CPU、GPU、NPU等不同技術方向上協同發力。全棧異構架構已成芯片大廠的必爭之地。
全棧異構布局持續提速
2025年底至今,CPU市場掀起一波小高潮,供需失衡態勢初現。有媒體報稱,英特爾、AMD的服務器CPU都出現產能提前售罄的情況,部分型號交貨周期達到6個月。
對此,有觀點認為,這一市場熱度標志著CPU在AI時代的價值回歸。此前,在AI計算中GPU憑借強大的并行計算能力占據絕對主導,CPU僅承擔基礎的通用計算任務,使用率相對有限。但隨著生成式AI、多模態模型的普及,人工智能計算范式將從“訓練主導”轉向“訓推并重”,尤其是AI進入智能體時代以后,任務調度、工具調用等環節對CPU的依賴將大幅提升。
這一改變將推動CPU使用率的攀升。在大模型預訓練和微調階段,CPU負責數據的存儲、分片與索引,將海量數據有序整理后輸送給GPU集群,為矩陣乘法等核心運算提供高效支撐;在多模態推理場景中,CPU承擔圖像、視頻的解碼任務,緩解GPU的算力壓力,保障多格式數據的順暢處理。
未來AI將向邊緣與端側深度滲透,場景的多樣性對算力將提出更加苛刻的要求,既要滿足高強度并行計算,也要兼顧低功耗、高靈活性,單一芯片無法覆蓋全場景需求,全棧異構必將成為行業標配。而這樣的趨勢判斷,使得國際與國內芯片廠商都選擇同步布局GPU、CPU乃至NPU技術,以實現多芯片的全棧異構協同,搶占市場先機。
英偉達、英特爾大廠發力
2020 年英偉達就計劃以400億美元價格從軟銀手中收購 Arm公司股權。這一交易雖然最終被叫停,但英偉達與Arm的合作并未結束,英偉達仍是Arm的主要用戶與合作伙伴。英偉達的Grace和Vera CPU,仍然使用Arm的知識產權和指令集。去年的GTC大會上,英偉達推出GB300平臺,整合Grace CPU與B300 GPU,大幅提升AI推理性能;英偉達還官宣下一代Vera Rubin平臺,采用定制Arm架構Vera CPU與Rubin GPU的組合,進一步突破算力與能效極限,瞄準下一代AI推理與智能體場景,以鞏固其在數據中心領域的主導地位。
英特爾在全力推進18A(1.8nm級)制程工藝落地的同時,也在加速補全GPU短板。在今年1月舉辦的CES展會上,英特爾發布了首款基于Intel 18A制程打造的計算平臺第三代酷睿Ultra處理器(代號 Panther Lake)。值得關注的是,2026年初英特爾正式任命原高通工程高級副總裁Eric Demers擔任首席GPU架構師。Eric Demers將負責設計AI加速GPU,進一步補強GPU研發實力,全力構建x86+GPU+NPU的全棧異構解決方案。
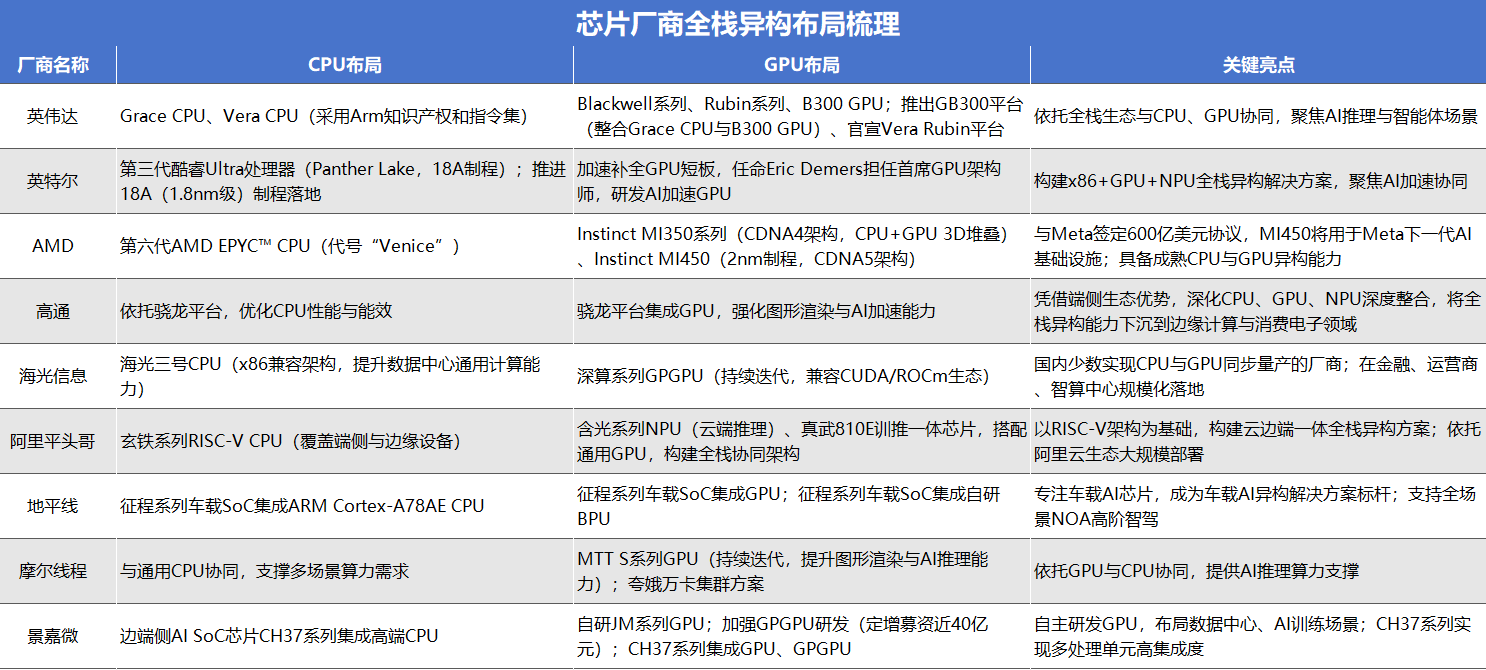
AMD一直具備CPU與GPU異構能力。去年4月,Instinct MI350 系列(CDNA4 架構)上市,主打 CPU+GPU 3D 堆疊 異構,AI 推理能效大幅提升,同時在銳龍AI系列中集成 XDNA 2 NPU,強化端側與嵌入式 AI。前文提到的MI450 將于今年發布,采用 2nm 制程工藝與 CDNA 5 架構,將被首批用于Meta的AI基礎設施當中。
高通則依托驍龍平臺實現CPU、GPU、NPU的深度整合。憑借端側生態優勢,高通將全棧異構能力下沉到邊緣計算與消費電子領域。
國內廠商自主突圍
國內芯片廠商立足自主可控的情況下,也在加速全棧異構領域的突圍。海光信息作為國內少數實現CPU與GPU同步量產的廠商,全力推進全棧異構布局。公司量產的海光三號CPU采用x86兼容架構,大幅提升數據中心通用計算能力,可高效承擔AI推理中的數據調度與預處理任務;同時,其深算系列GPGPU持續迭代,兼容CUDA/ROCm生態,在AI訓練與推理場景中實現國產替代,通過HSL高速互聯協議實現CPU與GPU的低時延協同,已在金融、運營商、智算中心等場景規模化落地,成為國內全棧異構布局的核心力量。
阿里平頭哥以RISC-V架構為基礎,構建云邊端一體的全棧異構方案。其玄鐵系列RISC-V CPU持續拓展生態,覆蓋端側與邊緣設備,為全棧異構布局提供通用計算支撐;同時,平頭哥推出含光系列NPU(用于云端推理)與真武810E訓推一體芯片,搭配通用GPU,形成CPU+GPU+NPU的全棧協同架構,依托阿里云生態實現大規模部署。
除了全棧布局的代表企業,國內眾多廠商在特定AI領域深耕細作,結合CPU或GPU技術形成特色異構解決方案。地平線專注于車載AI芯片領域,其征程系列車載SoC持續迭代,其中征程6系列采用第三代納什架構,集成18核心的ARM Cortex-A78AE CPU、200G FLOPS算力的GPU與四核自研BPU(NPU),最高AI算力達560TOPS,可接入24路攝像頭與多種傳感器,支持全場景NOA高階智駕,通過CPU、GPU、NPU的協同優化,成為車載AI異構解決方案的標桿。
摩爾線程聚焦通用GPU研發,其MTT S系列GPU持續迭代,提升圖形渲染與AI推理能力,推出的夸娥萬卡集群方案實現大規模AI訓練,補齊國產通用GPU短板,同時與通用CPU協同,為AI推理、工業視覺等場景提供異構算力支撐。
景嘉微在自研 JM 系列GPU的基礎上,通過定增募資近40億元,加強GPGPU研發,面向數據中心、AI訓練等場景。通過控股子公司無錫誠恒微電子,完成邊端側AI SoC芯片CH37系列的研發突破,采用高集成度單芯片架構,集成高端CPU、GPU、NPU、GPGPU、ISP等處理單元,提供64TOPS@INT8的峰值AI算力。
AI推理時代的算力競爭,已從單芯片參數比拼升級為全棧系統效率的較量。CPU價值的回歸、全棧異構的普及,將重塑全球芯片產業的競爭格局。國際大廠憑借技術積累、生態優勢與規模效應,加速推進全棧異構產品落地與生態卡位。國內廠商則需立足自主創新,在全棧布局與垂直領域雙線突破,加速實現國產替代。






